
Ksapa a conçu l’initiative SUTTI et les solutions associées afin de permettre la transformation du premier kilomètre des supply chains agricole : nous travaillons avec et pour les petits fermiers dans des programmes de moyenne et grande taille, en coopérant avec des acteurs industriels et financiers, des autorités publiques, des organisations de la société civile ou des universitaires dans plusieurs pays en Asie et en Afrique. À cette fin, nous avons conçu une suite SUTTI digitale permettant de diffuser du contenu et des informations aux petits exploitants, mais aussi de collecter des données auprès d’eux afin de contrôler notre impact social, économique et environnemental.
La question de la mesure de l’impact et donc de la qualité des données d’impact est dans ce cadre tout à fait clé pour la réussite de ces projets:
- Il nous faut monitorer et évaluer l’impact social, économique et environnemental de nos programmes afin de nous assurer de leur bonne utilité et de pouvoir ajuster le tir si les objectifs d’impact que nous poursuivons peinaient à être atteints : accès à la formation professionnelle de qualité et à la digitalisation, augmentation et diversification des revenus, inclusion sociale, impact sur l’intensité carbone des chaînes d’approvisionnement, etc.
- Les types de coalition organisées autour de nos programmes nécessitent une matérialisation de l’impact positif que nous apportons, qui sera le ciment de ces coalitions sur le long terme, alors que les parties prenantes impliquées ont toutes des objectifs et des agendas différents. Par exemple, nous travaillons au Sri Lanka avec les gouvernements sri lankais et français, le groupe Michelin, des experts dans divers domaines – agronomie, audit, IT, conseils juridiques, … – , des instituts de recherche, des universités, etc.
- Enfin, même si les 600 millions de fermes de moins de 2 Ha font vivre fort probablement plus du quart de l’humanité, force est de constater que ce pan de la population mondiale constitue un réel trou noir en matière de données, celles-ci demeurant rares, éparses et rarement comparables pour établir et comprendre les profils et les fonctionnements de petits fermiers pourtant totalement essentiels à l’alimentation mondiale et aux chaînes de valeur agro-industrielles
C’est pour cette raison entre autres que nous avons conçu la solution digitale “SUTTI Digital Suite”, venant dans un format hybride en appui du déploiement en présentiel de ces programmes :
- pour disséminer du contenu et des informations aux petits fermiers participants – e-learning, informations sur les prix ou les tournées de collecte, etc. -,
- mais également pour collecter des données auprès de ces mêmes fermiers – profil initial, P&L, geoplotting mais également enquêtes régulières
Cette solution est notamment pensée pour les environnements compliqués, avec peu d’accès à des terminaux récents, une connectivité limitée ou des difficultés de lecture : ainsi, la solution digitale SUTTI Digital Suite comprend une application fermiers multilingues, fonctionnant sur tous types de téléphone (pas seulement les smartphones), fonctionnant hors-ligne et utilisable par des personnes illettrées.
Elle comprend un outil de back-office pour administrer l’ensemble, mais également un outil de reporting permettant de suivre l’avancement du programme quotidiennement.
Le comité Data de SUTTI
La difficulté de collecter des données dans un environnement complexe est multiple :
- Tout d’abord, il faut disposer de moyens permettant la collecte non seulement au niveau des organisations de la société civile animant ces programmes, mais nous avons également fait le choix de les collecter directement auprès des petits fermiers, en développant nos solutions digitales. Collecte à laquelle les fermiers participants sont naturellement sensibilisés et formés.
- Mais les données collectées peuvent comporter des incohérences, des manques, s’appuyant sur des divergences d’interprétation ou des erreurs de saisie, voire des stratégies pour répondre en fonction d’attentes projetées.
- C’est d’autant plus difficile que les données collectées directement auprès des populations dites vulnérables sont relativement rares et que les méthodes pour les traiter et les interpréter sont manquantes.
- Enfin, pour se réclamer d’un impact positif, trois critères doivent classiquement être réunis: l’intentionnalité, l’additionnalité et la mesurabilité. Or si certains indicateurs d’impact sont relativement faciles à calculer, comme le nombre de personnes ayant accès au programme et ayant déclaré ne pas avoir eu accès à une formation professionnelle au cours des cinq dernières années, d’autres sont plus compliqués à mesurer ou à démontrer. Par exemple, le suivi des évolutions de revenus ne peut pas à lui seul mesurer l’additionalité de nos démarches : une évolution de revenus peut provenir des formations prodiguées ou des moyens apportés dans le programme, mais tout aussi de l’augmentation des cours mondiaux, des capacités de négociation des communautés fermières ou de l’évolution de la marge prise par les intermédiaires de la chaîne d’approvisionnement. Il faut ainsi intégrer dans la collecte des indicateurs réellement représentatifs de l’additionalité : par exemple, l’augmentation de rendement à la suite de changements de techniques ou de fournitures de méthodes pour lutter contre les maladies des plantes et arbres exploités, ou bien l’augmentation de revenus provenant des diversifications de culture préconisées dans le cadre du programme.
Des sources de données collectées inégales
Fort de ces principes, nous avons commencé à collecter des données, pour rapidement réaliser qu’elles étaient de qualité inégale, et qu’une partie de ces données étaient non exploitables, menaçant de rendre l’analyse de l’ensemble non signifiante.
Ainsi, des valeurs manquantes ou erronées (par exemple, des valeurs anormales qui sont impossibles à atteindre – par exemple, un prix de vente par kg représentant 100 fois l’indice mondial des matières premières) empêchent l’établissement de moyennes ou de corrélations qui nous permettraient de suivre l’impact du programme de manière significative, nous privant ainsi de moyens d’analyse pour ajuster nos actions. Mais ces problématiques peuvent potentiellement amoindrir notre capacité à rendre compte aux différentes parties prenantes (et notamment aux financeurs de ces programmes) avec un bon calibrage du niveau de qualité des indicateurs d’impact, sur lesquels les parties prenantes devraient pouvoir s’appuyer pour guider leurs actions ou communiquer à leurs propres parties prenantes.
Ce comité est composé de :
- Fatima Roudani, spécialiste ESG & Impact, ayant notamment été responsable de sujets big data ESG au sein d’établissements bancaires
- Edwige Rey, Associée du cabinet Mazar et spécialiste des sujets d’audit extrafinancier
- Nathan Hara, astronome spécialiste de l’utilisation des données pour la recherche d’exoplanètes
Il se réunit régulièrement pour guider et valider notre approche de data science et sa bonne intégration dans nos solutions SUTTI. Il nous a notamment permis de développer une approche en 3 temps, décrite ci-dessous (amélioration de la robustesse des données, calcul de KPI (indicateurs clés de performance) sur des données robustes, inférence d’impact de SUTTI Programme à toutes les données).

Étape 1 : Amélioration de la robustesse des données
L’amélioration de la robustesse des données peut être décrite comme la recherche de méthodes statistiques ou d’algorithmes appropriés pour repérer les valeurs aberrantes, signaler les données inutilisables ou trompeuses et corriger les données. En termes statistiques, une valeur aberrante est une observation qui se situe à une distance anormale des autres valeurs dans un échantillon aléatoire d’une population.
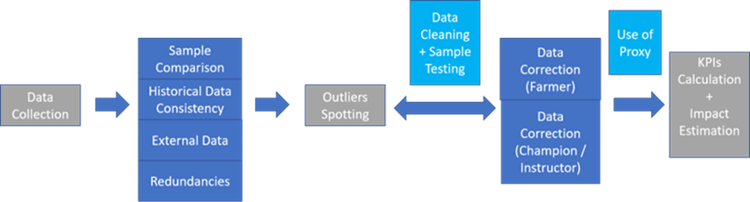
En ce qui concerne les méthodes de repérage des valeurs aberrantes, nous disposons principalement de quatre types de méthodologies ou sources de repérage des valeurs aberrantes : la cohérence des données historiques, la comparaison des échantillons, la comparaison des données externes et la redondance des données. Les détails de ces méthodes peuvent être décrits comme suit :
(1) Cohérence des données historiques. En ce sens, la valeur des données normales doit se situer dans une fourchette raisonnable (ni trop grande, ni trop petite) et les valeurs aberrantes sont celles qui se situent en dehors de cette fourchette. La vérification de la cohérence des données historiques est donc principalement basée sur la densité ou la distance. La méthode la plus courante est la règle des trois sigmas, travaillant autour des notions d’écarts-types autour de la moyenne. Typiquement, si un agriculteur produit régulièrement x kg par mois pendant 2 ans, une déclaration mensuelle x fois supérieure à la fourchette habituelle de déclaration sera considérée comme une « donnée aberrante ».
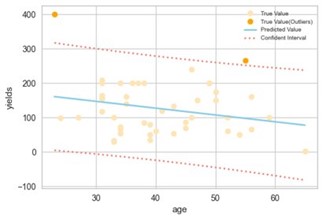
(2) Comparaison des échantillons. En utilisant cette approche, nous étudions la relation entre la variable ciblée et d’autres facteurs, et les valeurs aberrantes sont celles qui ne suivent pas la relation. Par exemple, nous avons trouvé une relation négative entre les rendements en caoutchouc et les âges. Par régression linéaire dans l’image suivante, les points orange foncé ne suivent pas ce type de relation sur la base des intervalles de confiance à 95 %. Par conséquent, nous les considérons comme des valeurs aberrantes suspectes : ils représentent des points de données qui diffèrent de manière significative de la moyenne ou de la fourchette habituelle d’un groupe de profils de fermiers comparables. Cela ne signifie pas nécessairement qu’ils seront définitivement exclus des calculs, mais ils seront examinés avec plus de prudence.
(3) Comparaison de données externes. Plusieurs sources de données externes sont envisagées : FAO, OCDE, Banque mondiale, UNESCAP, etc. Par exemple, un agriculteur particulier est susceptible (selon les pays) de vendre sa production à un prix allant de 40 à 95% du prix mondial (selon la localisation, le pays, …) – nous utilisons les données externes de gapkindo.com (Natural Rubber Price Watch in a few ASEAN countries fourni par l’institution indonésienne Gap Kindo) pour détecter les valeurs aberrantes pour les prix du caoutchouc dans nos programmes indonésiens. D’autres calculs similaires peuvent être effectués sur le rendement par hectare. D’après ces données externes, nous avons constaté que la série temporelle de la différence des prix du caoutchouc (par exemple, le prix du caoutchouc d’aujourd’hui moins le prix du caoutchouc d’hier) est stationnaire (stable) et nous utilisons donc ARIMA(1,1,1) (un modèle classique de série temporelle) pour modéliser le prix du caoutchouc. Nous pouvons donc utiliser ce modèle ARIMA pour prédire le prix du caoutchouc sur notre propre ensemble de données, effectuer la comparaison entre les valeurs prédites et les valeurs réelles, et les valeurs aberrantes sont donc celles qui se situent en dehors des intervalles de confiance générés lors de l’ajustement du modèle.
(4) Redondance des données. Il y a redondance des données lorsque le même élément de données existe à plusieurs endroits. Cela se produit généralement lorsque la conception de l’ensemble de données n’est pas appropriée. Je peux aider à repérer certaines personnes dont les réponses peuvent être incohérentes ou instables. Avant de repérer les valeurs aberrantes, il est nécessaire de vérifier la redondance des données et de réajuster la structure de la base de données si nécessaire.
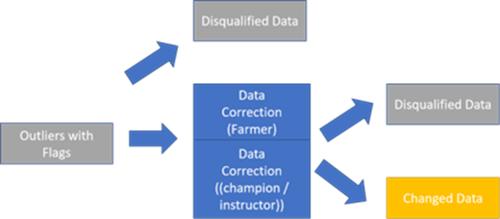
Quant à la correction des données, la manière la plus efficiente est qu’elle soit effectuée au travers de routines d’analyse pré-configurées aboutissant à un retraitement ou une confirmation manuelle, par des agriculteurs, des champions agricoles ou des instructeurs. Comme le montre l’image suivante, il est inévitable que seule une partie des valeurs aberrantes puisse être finalement corrigée, mais cela permet de s’assurer que les indicateurs-clés de performance (ICP ou « KPIs », Key Performance Indicators) ne sont donc calculés que sur des données robustes (c’est-à-dire des données normales avec des valeurs aberrantes corrigées).
Étape 2 : Calcul de l’ICP sur la base de données robustes
Deuxièmement, nous calculons les ICP sur la base de données solides. La conception des ICP se concentre principalement sur trois aspects :
– Nous voulons mesurer le nombre et la composition des bénéficiaires du programme SUTTI et le type de public concerné. Par exemple, le nombre de personnes touchées (bénéficiaires directs et indirects, % de femmes, % de jeunes…).
– Nous voulons mesurer l’accès à la formation professionnelle permis par les programmes SUTTI. Par exemple, le volume de formation professionnelle en heures/personne (à la fois en personne et numériquement).
– Impact sur l’augmentation et la diversification des revenus.
– Facultatif : piégeage du carbone ou évitement de l’émission de GES
Par conséquent, il existe principalement trois types d’indicateurs clés de performance dans les programmes SUTTI : le nombre de participants aux programmes SUTTI, la formation professionnelle et l’impact sur les revenus des petits exploitants agricoles. Cette approche est également adaptée à la qualification et au suivi des projets carbone, par exemple : le carbone séquestré ou les émissions de gaz à effet de serre évitées pourraient être suivis grâce à une collecte de données à grande échelle directement auprès des agriculteurs et complétés par des approches telles que le compte carbone, surveillance par satellite, etc.
Pour le premier type (nombre de personnes touchées), il s’agit de tous les types de dénombrement des participants, en fonction du sexe, de l’âge, de la parenté, de l’emploi, etc. Exemples : nombre de participants actifs, nombre de bénéficiaires directs, nombre de personnes dont les moyens de subsistance seront affectés, etc.
Pour le deuxième type (volume de formation professionnelle), il s’agit principalement d’évaluer l’évolution de la formation, comme les heures de formation des cours. Exemples : heures de formation en personne, nombre de personnes accédant au renforcement des capacités sur l’application SUTTI, etc.
Pour le troisième type (impact sur l’augmentation et la diversification des revenus), plusieurs dimensions sont prises en considération.
En ce qui concerne l’impact sur les revenus, l’équation peut s’écrire comme suit : revenus = rendement × prix × hectares. Dans cet ICP, nous voulons savoir de quelle partie provient l’augmentation des revenus : rendement, prix ou hectares, ce qui exclut d’autres variables qui peuvent également affecter les revenus. En outre, il vise à mesurer la relation entre l’augmentation des revenus et la diversité des activités des agriculteurs (potentiellement positive).
Dans ce cas, notre programme tient également compte de l’augmentation de la productivité et de la diversification, en incluant des indicateurs clés de performance relative à la production agricole (rendement de la culture principale, productivité de la culture principale, etc.), des indicateurs clés de performance relative à la protection des cultures (utilisation d’engrais, utilisation de pesticides, utilisation de médicaments intrants, etc.
Étape 3 : Inférence d’impact SUTTI pour toutes les données
La nécessité d’inférer l’impact est due à deux raisons. D’une part, seules les performances des agriculteurs ayant répondu sont observables, alors que nous nous intéressons davantage à l’impact général. D’autre part, seule une partie des valeurs aberrantes est finalement corrigée et les indicateurs clés de performance sont donc calculés sur des données robustes.
Dans ce cas, nous procédons à l’inférence d’impact. L’idée de base de l’inférence d’impact est simple : nous estimons l’impact sur les données de l’échantillon sur la base de certains modèles classiques (par exemple, le modèle de difference-in-difference), puis nous procédons à des ajustements en fonction du biais (par exemple, en introduisant d’autres variables dans le modèle, ou en modifiant la structure du modèle). Nous pouvons donc supposer que les résultats estimés du projet basés sur les données de l’échantillon correspondent à l’impact sur l’ensemble des données. L’équation des données estimées sur les données de l’échantillon s’écrit comme suit : impact estimé du programme SUTTI = la valeur réelle de l’ICP – la valeur contrefactuelle de l’ICP (c’est-à-dire la valeur qu’aurait l’ICP s’il n’y avait pas de programme SUTTI).
Par exemple, supposons que dans les données du programme SUTTI, nous ayons 1000 agriculteurs et que seules les données de 600 agriculteurs soient robustes. Tout d’abord, nous procédons à une inférence d’impact sur ces 600 agriculteurs et, après calcul, nous constatons que leur revenu moyen augmente de 1 000 dollars par an. Nous nous rendons ensuite compte que ces agriculteurs sont plus jeunes par rapport à l’ensemble des données, et qu’il est plus facile pour les jeunes agriculteurs d’accepter une nouvelle technologie et que projeter leur augmentation moyenne sur l’ensemble des participants serait trop optimiste. Nous procédons donc à quelques ajustements (qui pourront faire l’objet d’un prochain article) tenant compte de la répartition statistique de l’échantillon des « répondants » mais aussi de l’ensemble des participants, et l’impact final estimé sur le revenu des agriculteurs est par exemple une augmentation de (1000 – x%) dollars par mois sur l’ensemble des participants.
Le modèle comprend des variables de contrôle parce que ces variables sont celles qui peuvent également avoir une influence sur les variables de résultats (ICP). Par exemple, nous introduisons l’âge et le sexe comme variables de contrôle lorsque nous estimons l’impact du SUTTI sur la productivité des cultures principales. Il ne fait aucun doute que plus nous introduisons de variables de contrôle connexes pertinentes, plus l’impact estimé sera précis.
Quant au biais de sélection, il s’agit du biais qui résulte de l’incapacité à garantir une randomisation correcte d’un échantillon de population, comme l’auto-sélection, le biais de survie, la présélection des participants, etc. Dans tous les cas, la solution la plus radicale consiste à savoir à quoi ressemble le biais de sélection exact dans l’ensemble de données, afin de pouvoir l’ajuster dans le modèle d’estimation.
Conclusion
En conclusion, nous considérons qu’il est fondamental de récolter des données d’impact auprès des bénéficiaires eux-mêmes, et que les solutions digitales développées permettent de collecter ces données, même dans des conditions d’accès difficiles. Couplées à d’autres modes de collecte par les instructeurs, elles permettent de recueillir les déclarations et avis des bénéficiaires des programmes, comblant ainsi des manques en matière de données sur les populations vulnérables comme documentant la mesure d’impact sur nos programmes.
Les approches de data science développées sous la supervision de notre comité Data permettent ainsi de traiter des masses de données significatives et d’en tirer analyses en profondeur et projections d’impact qui sont largement applicables hors du champ agricole pour lequel elles ont été conçues : ainsi, ces solutions ont vocation à s’appliquer également à des études de masse sur les questions de revenus décents ou de conditions de travail des ouvriers.
20+ years of experience in investment & asset management.
Raphael Hara works on relationships between finance and sustainability, in particular through the development and management of impact investment funds and projects.















Xianlin Ding
Xianlin intervient en tant que Data Analyst chez Ksapa. Il assure entre autres la gestion et l’analyse des données recueillies auprès des populations agricoles via l’application SUTTI, ainsi que la mise en place des dispositifs et indicateurs de suivi d’impact. Etudiant à l’ENSAE Paris en Data Sciences et Sciences Sociales et Sciences Po Paris en Politique Économique Internationale, Xianlin a déjà travaillé en statistique appliquée (estimation du PIB en Chine, prévision du prix de l’immobilier au Japon…). Il a auparavant analysé des données provenant de « European Societies » afin de faire ressortir les éléments appréciés de la revue. Xianlin parle mandarin, anglais, français et espagnol.